
The Data Vault 2020
A while ago I came across the “data vault” concept. I felt I could “relate” to it since it formalizes many of the design techniques and strategies I have been using for years. It’s a scalable, hybrid approach combining the best of legacy relational database and star schema designs.
The approach has been around for 20 years. It’s a concept attributed to database author and consultant Dan Linstadt. According to Linstadt:
“The data vault is a detail oriented, historical tracking and uniquely linked set of normalized tables that support one or more functional areas of business. It is a hybrid approach encompassing the best of breed between 3rd normal form (3nf) and star schema. The design is flexible, scalable, consistent and adaptable to the needs of the enterprise. It is a data model that is architected specifically to meet the needs of today’s enterprise data warehouses.”
History Repeats Itself
Architecturally, a data vault is similar to a typical “data warehouse”.
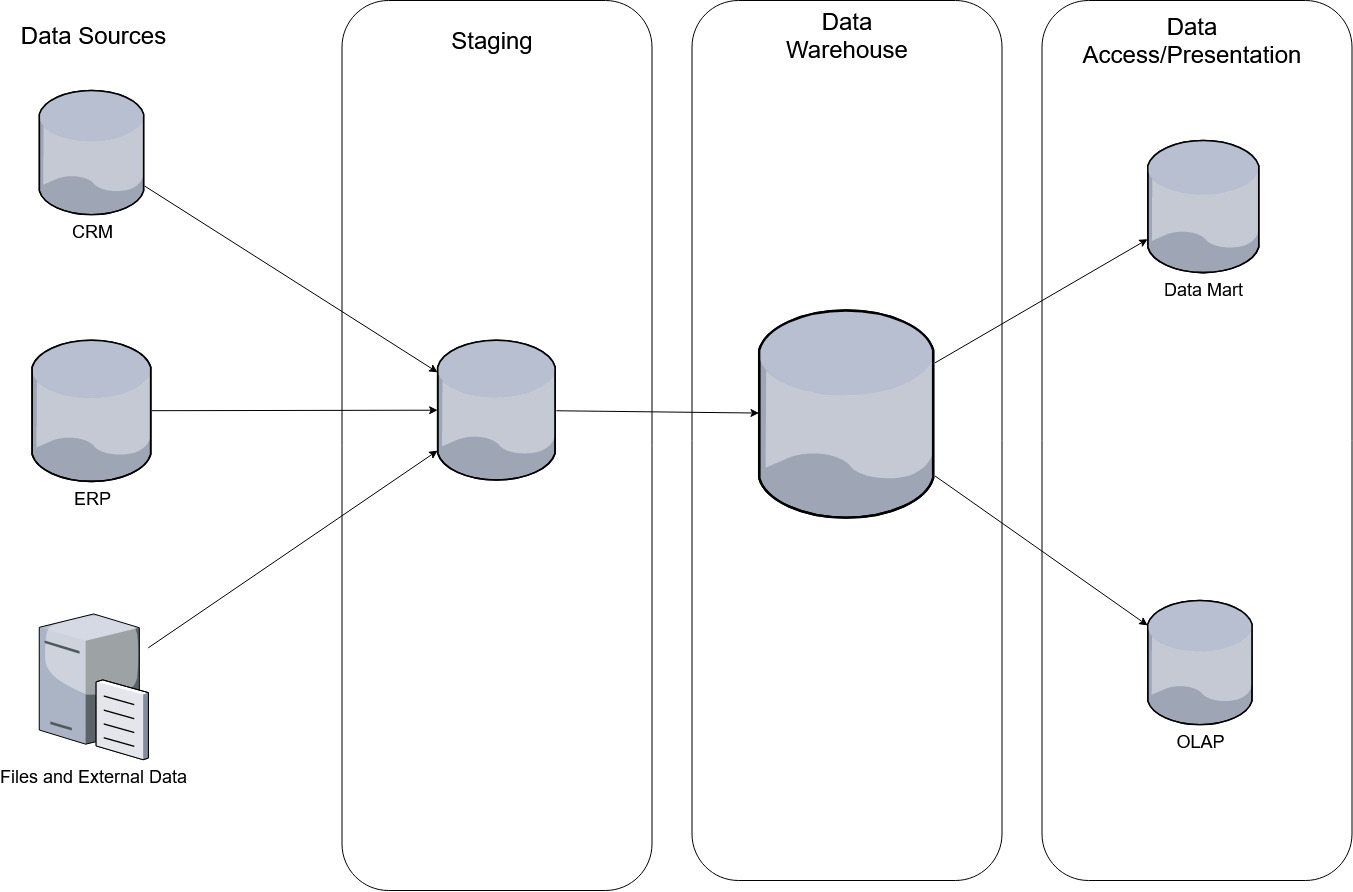
Figure 1.- Data Warehouse Design circa 2005
A Point of Departure
The process has evolved a bit from the previous diagram. Today's data vault architecture might look something like this:
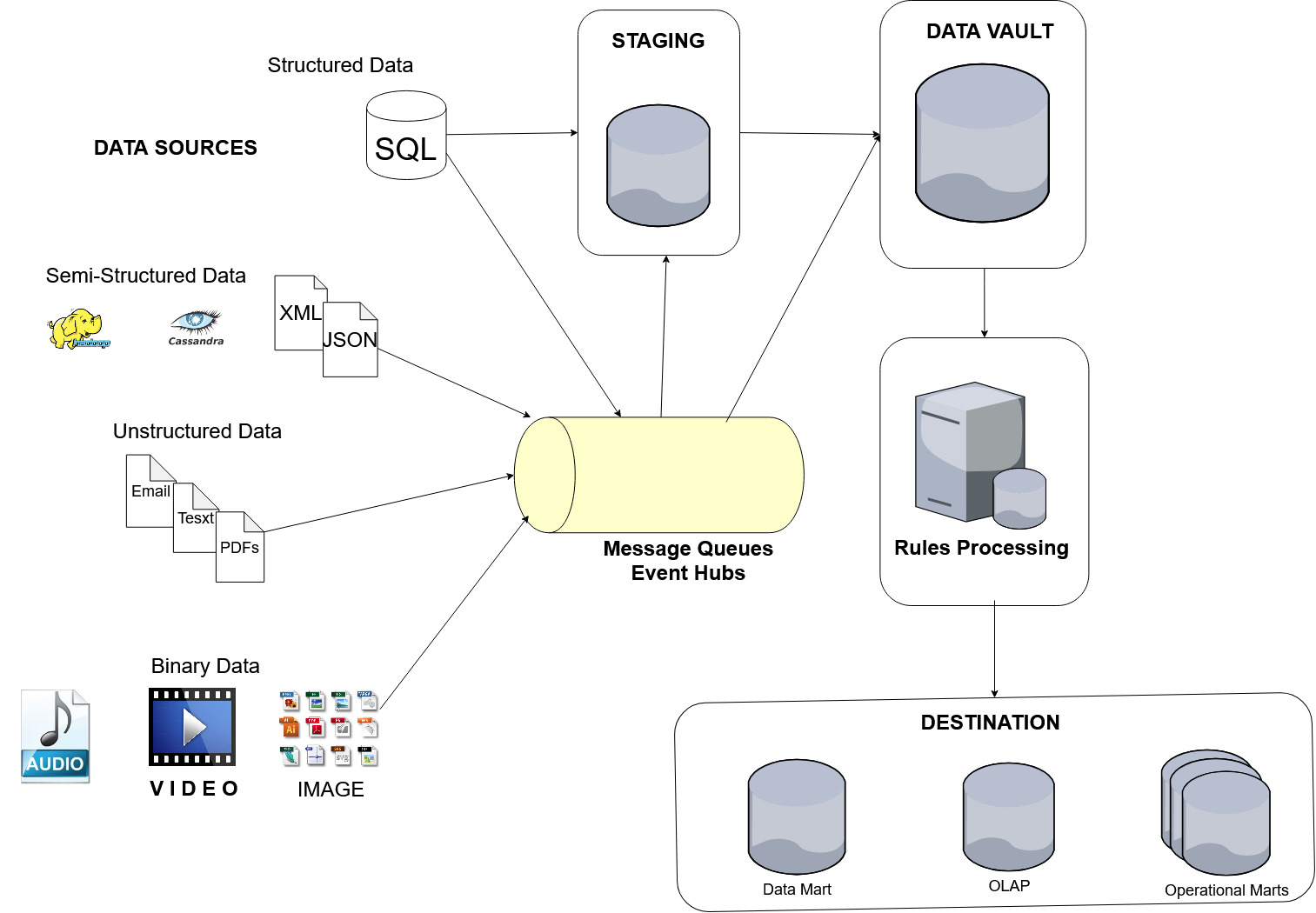
Figure 2.- Today
DATA SOURCES
Today, source data comes from a variety of structured, semi-structured, unstructured or binary sources. In high volume situations it's often routed through a message queue or event hub on its way to staging. This step helps efficiently manage the flow and volume of data making the entire process much more scalable.
STAGING
Staging is where all “as is” source data initially lands or passes. Modeled after the source data. The idea is to load data as is, warts and all. You could say that this is an extract-load-transform (ELT) process rather than the more traditional extract-transform-load (ETL) process.
As noted in one of my previous blogs, it’s always better to have data “pushed” from the original source. That is, the original source should "own" the process.
The staging database generally maintains no history and applies only “hard” rules such as data types and additional meta data used for tracking and auditing data. Complex business rules and transformations are located downstream.
DATA VAULT
This is the point of departure from the conventional data warehouse star or snowflake design.
You can think of it as an interim approach that helps improve the efficiency and ease of managing data, especially data changes. The vault contains original source data and subsequent changes ADDED to the vault. No UPDATES (Delete-Insert) or DELETES allowed.
There are three main table constructs, called “Hub”, “Satellite” and “Link”. I use my own naming conventions CORE, ITEM AND LINK
Conceptually, a CORE (or HUB) table maintains a unique business key. It can be a single value or a composite. The single or composite business key is hashed for improving data integrity. The load date and source for the data is also included.
LINK tables maintain foreign keys that define CORE table and ITEM table relations.
ITEM (or Satellite) tables maintain attributes that define the business key stored in CORE tables. They often include non-identifying objects like cost, color, height, weight, description detail, etc. Items can also be split or partitioned by frequency.
Here’s a section of a design for a project service billing data vault.
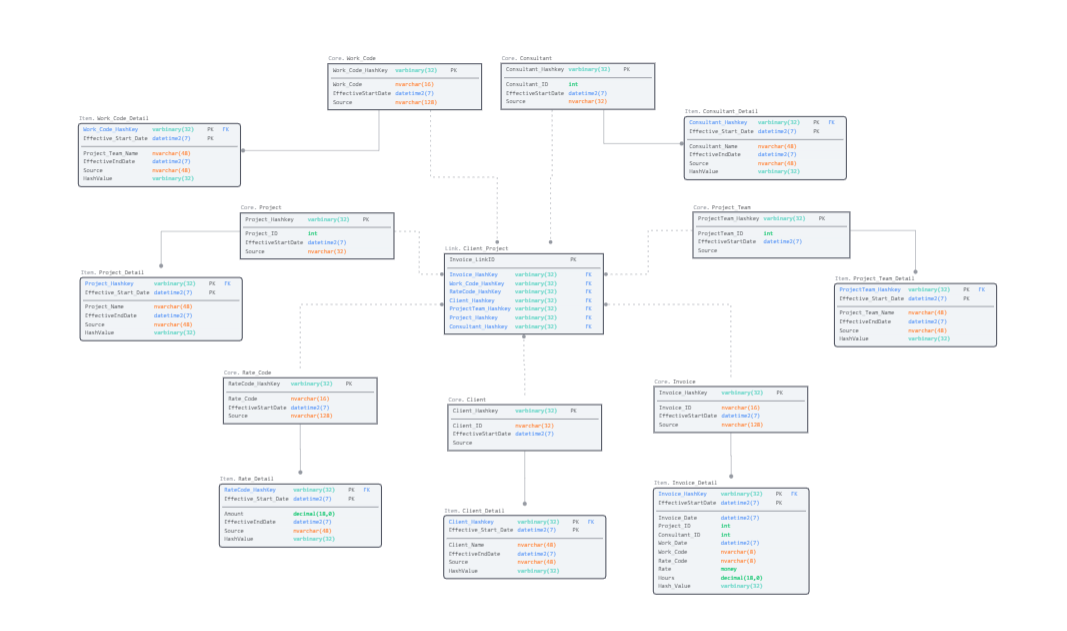
Figure 3. Service Billing Sample
After data lands in the vault, you apply rules and transformations before sending it to its destination.
DESTINATION
Ideally, the destination is a platform for providing self-serve business intelligence information for end users. Using the data vault as the source for custom reporting or OLAP star schema data marts or master data destinations. And optionally, building out operational marts to maintain error, performance and meta data.
The WHY
There are genuine advantages using a data vault approach:
- Low data redundancy
- Flexibility to create and drop relations “on the fly"
- Emphasis on historical change tracking
- Easier data management by isolating business keys from descriptive attributes
- Easier data management by using meta-data like data source and effective dates
- Easier extensibility making an agile project approach practical
- High scalability
- Load processes can easily run in parallel
- Data is easy to audit
Final Thoughts
A data vault methodology is an evolutionary approach worth looking into. Anything to make what can easily become an overly complex, inefficient process is worth the time. Especially if you can learn something, improve it and add it to your set of tools.
Be well.

Leave a Comment:
Here are some useful categories to links that will help decipher some of the mysteries of SQL Server and other data technologies
Categories
Azure
- AMQP Video
- Azure Pricing Calculator - Estimate your bill
- Azure Service Bus Messaging Deep-Dive Video
- Azure Service Bus—Cloud Messaging Service
- Everything You Need to Know About Azure Service Bus Brokered Messaging (Part 1)
- Google Bigquery
- Hidden Costs in the Cloud, Part 2: Windows Azure Bandwidth Charges
- Introducing Windows Azure Service Bus for Visual Studio Developers Video
- Messaging in Azure: Event Hubs, Service Bus, and Relay Video
- Redshift
- SQL Database – Cloud Database as a Service
- SQL Data Warehouse
- SQL (PaaS) Database vs. SQL Server in the cloud on VMs (IaaS)
- SQL Server virtualization – Azure SQL Server VM
- Stream Analytics - Real-time data analytics
- Azure Pricing Calculator - Estimate your bill
Backup And Restore
- Backup and Recovery in Configuration Manager
- Centralized management: Tips for Managing Backups on Multiple Servers
- How to backup SQL Server databases to Microsoft Azure
- How to increase SQL 2008 R2 Backup throughput
- How To Restore the Master Database in SQL 2012
- Filegroup Backup and Restore in SQL Server
- Purging MSDB Backup and Restore History from SQL Server
- Retore SQL Server database to different filenames and locations tutorial and example
- SQL SERVER – FIX : Error 3154: The backup set holds a backup of a database other than the existing...
- SQL Server 2014 Backup Basics
- SQL Server Backup
- SQL Server BACKUP DATABASE command tutorial and example
- SQL Server Backup Encryption
- SQL Server: Understanding Logging and Recovery in SQL Server
- Understanding SQL Server Log Sequence Numbers for Backups
- Using Transparent Data Encryption
- Veeam Backup Tool
- Centralized management: Tips for Managing Backups on Multiple Servers
Clustering and High Availability
- AlwaysOn Availability Groups: Step by Step Setup
- An Introduction to SQL Server Clusters with Diagrams
- Configure SQL Server AlwaysOn Availability Group on a Multi-Subnet Cluster
- DBA 173-Patching Or Updating AlwaysOn Availability group Replicas in SQL Server Best Practices Video
- How to Install a Clustered SQL Server 2012 Instance – Part 2
- How to Patch a SQL Server Failover Cluster
- How to Set Up SQL Server Denali Availability Group
- Lync 2013 and Database Mirroring and a little basic troubleshooting
- Migrating MS SQL Cluster to New Shared Storage
- Monitor SQL Server AlwaysOn Availability Groups
- Powershell Scripting: Installing SQL / Setting up AlwaysOn Availability Groups
- So, You Think You Want SQL AlwaysOn Availability Groups?
- SQL 2012 Failover Cluster Build (Step by Step) – Part 1: Installing SQL 2012
- SQL Server DBA Tutorial 26-How to Install Service Packs,Hot Fixes and Windows Patches in Cluster Video
- SQL Server Disaster Recovery VS. High Availability (Update)
- SQL Server failover cluster rolling patch and service pack process
- SQL Server Failover Clusters
- Stack Overflow Architecture - High Scalability -
- Tiered Support Model for Database Monitoring & Delivery
- Windows Server 2012: Building a Two-Node Failover Cluster
- An Introduction to SQL Server Clusters with Diagrams
Deploy
- Automating SQL Server Database Deployments: Scripting Details
- Automating SQL Server Database Deployments: A Worked Example
- Deploy a Data Tier Application
- SSIS Deployment with PowerShell: Adding Environment References
- Automating SQL Server Database Deployments: A Worked Example
Design
- Relational Database Design
- Relational Database Concepts
- Five Simple Database Design Errors You Should Avoid
- Important Database Design Rules
- Ten Common Database Design Mistakes
- Tips for Better Database Design
- Kimball Dimensional Modeling
- Kimball-Inmon Dimensional Modeling Comparison
- Data Lake Design
- Enterprise Data Lake Design
- Web Sequence Diagram
- Datanamic Dezign Tool
- Building a Rule Engine with SQL Server
- Code Effects: .NET Business Rules Engine
- Relational Database Concepts
ftp
- CrushFTP - Enterprise Grade File Transfer for Everyone
- Filezilla
- WatchFTP - Monitor an FTP Site for New and Changed Files
- Filezilla
Install
- How to install SQL Server 2008 32Bit on Windows 2008 X64
- 12 Essential Steps After Installing SQL Server
- How to install SQL Server 2014
- How to install NetFx3 on Windows Server 2012 (required by SQL Server 2012
- How to configure SQL Server to listen on a specific port
- Error when using MS SQL Server "Named Pipes Provider: Could not open a connection to SQL Server"
- SQL Server Installation Using Powershell
- 12 Essential Steps After Installing SQL Server
Licensing
- SQL Server 2017 Pricing and License Guides
- Microsoft Licensing Simplified Into Seven Rules
- Introduction to SQL Server Licensing
- Microsoft Licensing Simplified Into Seven Rules
Maintenance and Monitoring
- Automate and Improve Your Database Maintenance Using Ola Hallengren's Free Script
- Clear Cache and Buffer of Stored Procedure in SQL Server
- Dealing with high severity errors in SQL Server
- Different Status of a SPID in SQL Server and What do they mean
- Eight Steps to Effective SQL Server Monitoring
- Great SQL Server Debates: Buffer Cache Hit Ratio
- How to Install Service Packs,Hot Fixes and Windows Patches in Cluster Video
- How to Run ChkDsk and Defrag on Cluster Shared Volumes in Windows Server 2012 R2
- How to shrink the tempdb database in SQL Server
- Lock Pages in Memory in SQL Server on VMware – Why or Why Not
- MaxTokenSize and Windows 8 and Windows Server 2012
- Memory Manager surface area changes in SQL Server 2012
- Reduce Time for SQL Server Index Rebuilds and Update Statistics
- Registering SQL Server instances for easier management
- SQL Server 2012 Auto Identity Column Value Jump Issue
- SQL Server Backup, Integrity Check, Index and Statistics Maintenance
- SQL Server Deadlocks by Example
- SQL Server Monitoring with SolarWinds Server and Application Monitor
- SQLDBA: WmiPrvSE.exe blocking SQL Server 2008 R2 SP1 setup
- Tips for Rebuilding Indexes - SQL Server Performance
- Top Tips for Effective SQL Server Database Maintenance
- We couldn't complete the updates, Undoing changes
- Windows Update Database Corruption
- What does a well maintained Team Foundation Server look like?
- Why you should not shrink your data files
- Clear Cache and Buffer of Stored Procedure in SQL Server
Migrate
- A Faster Way to Migrate SQL Server Instances!
- Download Microsoft SQL Server 2008 Upgrade Advisor from Official Microsoft Download Center
- Getting Started with dbatools
- How to migrate SQL Server from one machine to another
- How to Move Master Database to a New Location in SQL Cluster
- How to move the Master database
- How to Upgrade to SQL Server 2008 from SQL Server 2000
- How-To: Migrate MS SQL Cluster to a New SAN
- Migration SQL Server 2000 to SQL Server 2008
- Moving Databases on a SQL Server Cluster 2008 R2 to A New SAN
- SQL Server Database Migration Checklist
- Steps to Migrate from SQL Server 2000 to SQL Server 2014
- sys.sysprotects (Transact-SQL)
- Upgrading To SQL 2012: Ten Things You Don't Want To Miss
- What to Consider When Creating SQL Server Database Migration Plan
- Download Microsoft SQL Server 2008 Upgrade Advisor from Official Microsoft Download Center
Optimize
- A Sysadmin's Guide to Microsoft SQL Server Memory
- Building Microsoft MEAP: Scaling Out SQL Server
- Did You Give SQL Server 2012 Standard Edition Enough Memory?
- Finding the Source of Your SQL Server Database I/O
- First Responder Kit for SQL Server
- How much memory does my SQL Server actually need?
- How to Identify Slow Running Queries with SQL Profiler
- How to Move TempDB to New Drive in SQL Server
- Introduction to Change Data Capture (CDC) in SQL Server 2008
- Manage Metadata When Making a Database Available on Another Server Instance (SQL Server)
- memcached - a distributed memory object caching system
- Policy-Based Management
- Resource Governor
- SafePeak for SQL Server Performance
- Simple Query tuning with STATISTICS IO and Execution plans
- SQL Server 2012 Performance (SQL)
- SQL Server Database File I/O Report
- SQL Server Extended Events A Day Series
- SQL Server Indexed View Basics
- SQL Server Perfmon Counters Tutorial
- SQL Server Performance Howlers
- SQL Server: Calculating Running Totals, Subtotals and Grand Total Without a Cursor
- SSIS 2012 Projects: Deployment Configurations and Monitoring
- Stop Shrinking Your Database Files. Seriously. Now.
- Tuning the Performance of Change Data Capture in SQL Server 2008
- Upgrading To SQL 2012: Ten Things You Don't Want To Miss
- Why Update Statistics can cause an IO storm
- Building Microsoft MEAP: Scaling Out SQL Server
Planning
- A High Level Comparison Between Oracle and SQL Server
- Data Warehouse in The Cloud
- Dev, Test and Production SQL Server environments
- Developer's Guide to Faking Database Administration
- Features Supported by the Editions of SQL Server 2014
- History of SQL Server Features
- How to determine the version, edition and update level of SQL Server and its components
- How to use MAP Tool–Microsoft Assessment and Planning toolkit
- Implementing a Business Rule Engine
- Introduction to Polybase
- Provisioning a New SQL Server Instance – Part One
- Provisioning a New SQL Server Instance – Part Two
- Provisioning a New SQL Server Instance – Part Three
- SQL Server on VMware Availability and Recovery Options
- Transparent Data Encryption
- What-If Analyzer
- Wow… An online calculator to misconfigure your SQL Server memory!
- Understanding OData v3 and WCF Data Services 5.x
- Data Warehouse in The Cloud
Replication
- 01 docs.microsoft Configure Windows Service Accounts and Permissions
- 02 docs.microsoft System Stored Procedures Concepts
- 03 docs.microsoft Security Best Practices
- 04 docs.microsoft Best Practices for Replication Administration
- 05 docs.microsoft Agent Security Model
- 06 docs.microsoft Stored Procedures (Transact-SQL)
- 07 docs.microsoft sp_addpublication_snapshot (Transact-SQL)
- 08 docs.microsoft sp_addsubscription (Transact-SQL)
- 09 docs.microsoft sp_addlogreader_agent (Transact-SQL)
- Fundamentals of SQL Server 2012 Replication
- Monitoring SQL Server Replication
- Replication Error "The Process Could Not Execute"
- SQL Server Replication Beginner to Expert Part2 Video
- SQL Server Replication Step by Step
- SQL Server: Adding new article without generating a complete snapshot
- Start/Stop SQL Server Replication Agent using TSQL
- 02 docs.microsoft System Stored Procedures Concepts
Scripting
- 15 Ways to Bypass the PowerShell Execution Policy
- dbatools – best practices and instance migration module
- DTEXEC Command Line Parameters Using Command Files
- dtexec Utility
- Error: Creating an instance of the COM component with CLSID from the IClassFactory failed
- Handling-errors-in-sql-server-2012
- How to Map Network Drives From the Command Prompt in Windows
- How to Run a PowerShell Script from Batch File
- How to run a Powershell script from the command line and pass a directory as a parameter
- How-to-map-network-drives-from-the-command-prompt-in-windows
- How to pass in parameters to a sql server script called with sqlcmd
- MS-DOS dir command help
- Powershell Executing Scripts
- Powershell File Reading Options
- PowerShell to Discover, Diagnose, and Document SQL Server
- Robocopy "Robust File Copy"
- Running Windows PowerShell Scripts
- Setting the PowerShell Execution Policy
- SQL Full Outer Join
- SQL Server Common Table Expressions (CTE) Basics
- SQL Server SQLCMD Basics
- SQL Server Cross Apply and Outer Apply
- Use PowerShell to Change SQL Server Service Accounts
- Use PowerShell to Explore Nested Directories and Files
- windows - How to run a PowerShell script?
- Windows Azure SQL Database Management with PowerShell
- Writing SQL Server Service Broker Applications Across Databases
- dbatools – best practices and instance migration module
Security
- Database Security Best Practices
- How to Get SQL Server Security Horribly Wrong
- Schema-Based Access Control for SQL Server Databases
- Claims Based Authentication
- Securing and protecting SQL Server data, log and backup files with TDE
- Security Issues with the SQL Server BUILTIN Administrators Group
- Add Any User to SysAdmin Role – Add Users to System Roles
- Security Auditing With ApexSQL Audit
- Understanding SQL Server fixed database roles
- SQL Server DBA Tip: Credentials and Proxies
- Create a Credential in MS SQL Server 2012
- How to Get SQL Server Security Horribly Wrong
ServiceBroker and XML
- Ad-Hoc XML File Querying
- Building a Distributed Service Broker Application
- Building Reliable, Asynchronous Database Applications Using Service Broker
- Configuring Service Broker for Asynchronous Processing
- Configuring SQL Server Service Broker
- Deep Shah's Blog: Fastest way to parse XML in SQL Server
- How to troubleshoot Service Broker problems
- Importing and Processing data from XML files into SQL Server tables
- Importing XML file into SQL Server is too slow
- Load XML into Table using OPENQUERY BULK INSERT
- Managing SQL Server Service Broker Environments
- Manipulating XML Data in SQL Server - Simple Talk
- Monitoring and Troubleshooting Service Broker
- MSBI Blog: XML task in SSIS with example
- RabbitMQ - Getting started with RabbitMQ
- Service Broker Advanced Basics Workbench
- Service Broker, not ETL
- Service Broker Wait Types
- Service Broker: Scalable Web Service Calls From SQL Database
- SQL Server Endpoints: Soup to Nuts
- SQL Server Service Broker Across Databases
- SQL Server Service Broker Explained
- SQLXML Bulk Loader Basics
- ssbdiagnose Utility (Service Broker)
- The XML Methods in SQL Server
- Understanding SQL Server Service Broker Authentication
- Building a Distributed Service Broker Application
SQL Server Agent
- Alerts and email Operator Notifications
- Different ways to execute a SQL Agent job
- Enable and Disable SQL Server Agent Jobs for Maintenance Mode
- Managing SQL Server Agent Job History Log and SQL Server Error Log
- Multiserver administration with master and target SQL Agent jobs
- Querying agent job status, executing and waiting for job completion from within T-SQL
- Querying SQL Server Agent Job History Data
- Querying SQL Server Agent Job Information
- Run a SQL Agent Job from a Windows BAT File
- Script and Migrate Agent Jobs between Servers using PowerShell
- Setting Up Your SQL Server Agent Correctly
- Different ways to execute a SQL Agent job
Storage
- Configuring the Storage Subsystem
- Designing and Administering Storage on SQL Server 2012
- SAN Best Practices
- Pure Storage for SQL Server
- Hybrid Storage
- Designing and Administering Storage on SQL Server 2012
SSAS
- Add Columns to a Table (SSAS Tabular)
- Implementing Dynamic Security in Tabular Models
- Process a SQL Server Analysis Services Cube Using an XMLA Query
- SSAS Tutorial
- Implementing Dynamic Security in Tabular Models
SSIS
- Configure SSIS Logs
- Deploying Multiple SSIS Projects via Powershell
- Falsehoods Programmers Believe About CSVs
- Importing XML documents using SQL Server Integration Services
- Integration Services tutorial. Foreach Loop Container. Load multiple files Video
- Logging Error Rows with SQL Server SSIS
- sql server - How to load an XML file into a database using an SSIS package? - Stack Overflow
- SQL Server 2012 Integration Services - Using PowerShell to Configure Package Execution Parameters
- SQL Server Integration Services (SSIS) Part 1 - Getting Started Video
- SQL Server Integration Services (SSIS) Part 11 - Looping Over Files Video
- SSIS XML Task to Transform XML File Using XSLT
- SSIS-Fuzzy lookup for cleaning dirty data
- SSIS Deployment with PowerShell: Adding Environment References
- Top 10 Common Transformations in SSIS
- Top 10 SQL Server Integration Services Best Practices
- Validate XML File using SSIS XML Task
- Deploying Multiple SSIS Projects via Powershell
SSRS
- Administrating SQL Server Reporting Services
- Reporting Services Basics Intro
- Reporting Services Basics...Continued
- Script to Copy Content between Report Servers
- Reporting service ENCRYPTION KEY automated backup REPORT utility
- Migrating SQL Reporting Services to a new server by moving the Reporting Services databases
- Change Datasource of SSRS Report with Powershell
- How to Download All Your SSRS Report Definitions (RDL files) Using PowerShell
- Reporting Services Basics Intro