Designing a Data Source Discovery App - Part 11: New Year, New Architecture
by DL Keeshin
February 10, 2025
{kind=link}
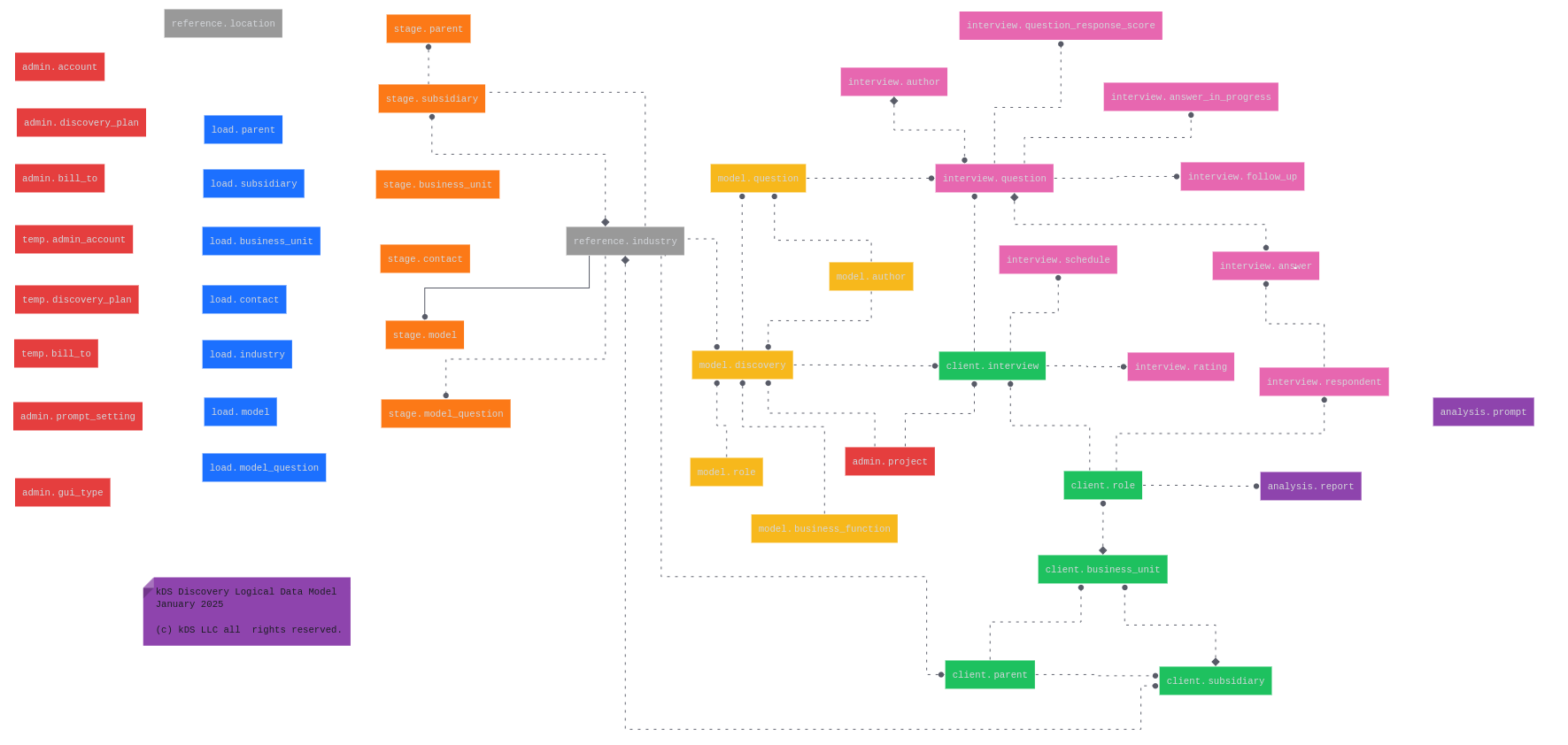
For my first post of 2025, I thought it would be appropriate to start with a review of significant kds_discovery database changes made since the fall of 2024. I'll walk you through our recent improvements and discuss naming conventions.
New Table Architecture
We've introduced several valuable additions to our database structure. In the admin schema, you'll find prompt_setting for managing LLM configurations, project for organizing interviews more effectively, and gui_type for streamlining HTML form controls.
CREATE TABLE IF NOT EXISTS admin.prompt_setting
(
name_ character varying(48) NOT NULL,
prompt_text text NOT NULL,
response_count integer NOT NULL,
create_date date NOT NULL,
created_by character varying(96) NOT NULL,
source_ character varying(96) NOT NULL,
modified_by character varying(96),
modified_date date,
CONSTRAINT prompt_setting_pkey PRIMARY KEY (name_)
);
CREATE TABLE IF NOT EXISTS admin.project
(
project_id uuid NOT NULL DEFAULT gen_random_uuid(),
name_ character varying(64) NOT NULL,
sponsor_ character varying(48),
manager_ character varying(48),
approval_date date,
start_date date,
end_date date,
create_date date NOT NULL,
created_by character varying(96) NOT NULL,
modified_date date,
modified_by character varying(96) ,
source_ character varying(96) NOT NULL,
CONSTRAINT project_pkey PRIMARY KEY (project_id)
);
CREATE TABLE IF NOT EXISTS admin.gui_type
(
gui_ character varying(48) COLLATE pg_catalog."default" NOT NULL,
CONSTRAINT gui_type_pkey PRIMARY KEY (gui_)
)
One of our most interesting changes is the revised reference.industry table. We've moved beyond simple NASIC codes to implement a more flexible system that combines code_source (such as NASIC) with the actual code to create a unique industry_hash_id. This approach gives us better data integrity while simplifying cross-referencing throughout the database.
CREATE TABLE IF NOT EXISTS reference.industry
(
industry_hash_id character varying(32) NOT NULL,
code_source character varying(32) NOT NULL,
code_ character varying(32) NOT NULL,
description_ character varying(255) NOT NULL,
version_ character varying(32) NOT NULL,
start_date date NOT NULL,
end_date date,
created_by character varying(96) NOT NULL,
create_date date NOT NULL,
modified_by character varying(96) ,
modified_date date,
CONSTRAINT pk_42_1 PRIMARY KEY (industry_hash_id)
)
Smarter Data Type Choices
We've made some practical adjustments to how we handle numerical data, particularly for company metrics:
- Annual revenue now uses character ranges (e.g., "100M to 500M") instead of specific numbers
- Employee counts follow the same pattern, using ranges like "100 to 1000"
These changes reflect a more practical approach to business data, where exact numbers aren't always available or necessary.
Enhanced Data Relationships
To strengthen our database's integrity, we've implemented some key structural improvements:
- Added a composite primary key to
stage.contactusing email_, parent_, subsidiary_, and business_unit - Established new foreign key relationships across the model, client, and interview schemas
AI Integration Done Right
One of our most forward-looking changes has been the introduction of rag_ columns throughout the database. These columns help us clearly distinguish between AI-generated data and real-world data, ensuring transparency in our data sources. If you're interested in the details, check out my previous blog post where I dive deeper into this topic.
New Views and Procedures
Views
We've created two essential views to improve our workflow:
stage.vw_contact_question_prompt: Streamlines LLM prompt retrieval for question generationinterview.vw_question_lookup: Provides efficient access to interview questions
Stored Procedures
We've migrated several key operations from Python scripts to stored procedures:
stage.up_insert_question: Handles question insertionstage.up_insert_model: Manages model insertion with natural keys and industry hash ID assignmentmodel.up_insert_model:Coordinates insertions across multiple tablesinterview.up_insert_answer: Moves answer storage from Python to database procedure
This shift to stored procedures helps maintain data integrity at the database level, reducing our reliance on application-layer logic.
A Word about Naming Conventions
Naming data objects is important. If you can't give an object like a database, schema, table, or column a good name, you haven't done your homework. Here are a few rules of thumb that I've developed over decades of work that I use in the kds_discovery data model design:
- Use short, singular, real words. Avoid abbreviations that are not words. Think of it this way: if it's not a Scrabble word, don't use it.
- Most table names are often nouns that represent things in the real world. For clarity I often combine table names with an action "verb" or process related to the data stored in the table separated by an underscore, like
order_insert. - Use schemas to name work flow processes or major system objects. For instance the kds_discovery database contains schemas like
load,stage,model,client,interview, andanalysis. Interestingly, schema names often appear in the early conceptual data design phase of a project--so please use them. They also can help organize security groupings with in a database. - One-word column names have an underscore at the end of the word, like email_ or order_. The logic behind this is to avoid using reserved words as column names. While there are other conventions for addressing this, an underscore at the end of a one-word column is the most efficient and easiest to read.
- Nowadays, I only use lower case letters.
Keep in mind, good naming conventions create self-documenting databases.
Looking Ahead
Over the past several months, we’ve made substantial improvements to the kDS Discovery database, refining its architecture for better efficiency, scalability, and AI integration. Key updates include new table structures for managing LLM configurations and project organization, enhanced data relationships with composite keys and foreign constraints, and smarter data type choices like range-based revenue and employee counts.
We’ve also introduced AI-ready features such as rag_ columns to distinguish generated content, improved industry classification using hash-based IDs, and migrated key operations from Python scripts to stored procedures for better data integrity. Additionally, new views and procedures streamline data retrieval and processing, making the system more robust.
Looking ahead, these advancements position us for continued growth and innovation. If your organization is interested in testing a beta version of the kDS Source Discovery App, we’d love to collaborate. Let us know in the comments below. Thanks for stopping by!