Designing a Data Source Discovery App - Part 16: Testing SQL Efficiency
by DL Keeshin
April 7, 2025
{kind=link}
LEFT JOIN vs. NOT EXISTS
Last time I talked about how the kDS Discovery App benefits from an insert only design approach. Today,I want to discuss a common SQL dilemma: using a LEFT JOIN with NULL check or a NOT EXISTS correlated subquery to find records that don't exist in another table. I decided to test both approaches using real data with PostgreSQL's EXPLAIN ANALYZE feature. The results revealed surprising performance differences despite the database using identical execution plans for both queries. In this post, I'll share what I discovered about these two SQL patterns and why one consistently outperformed the other for this specific use case.
The Problem
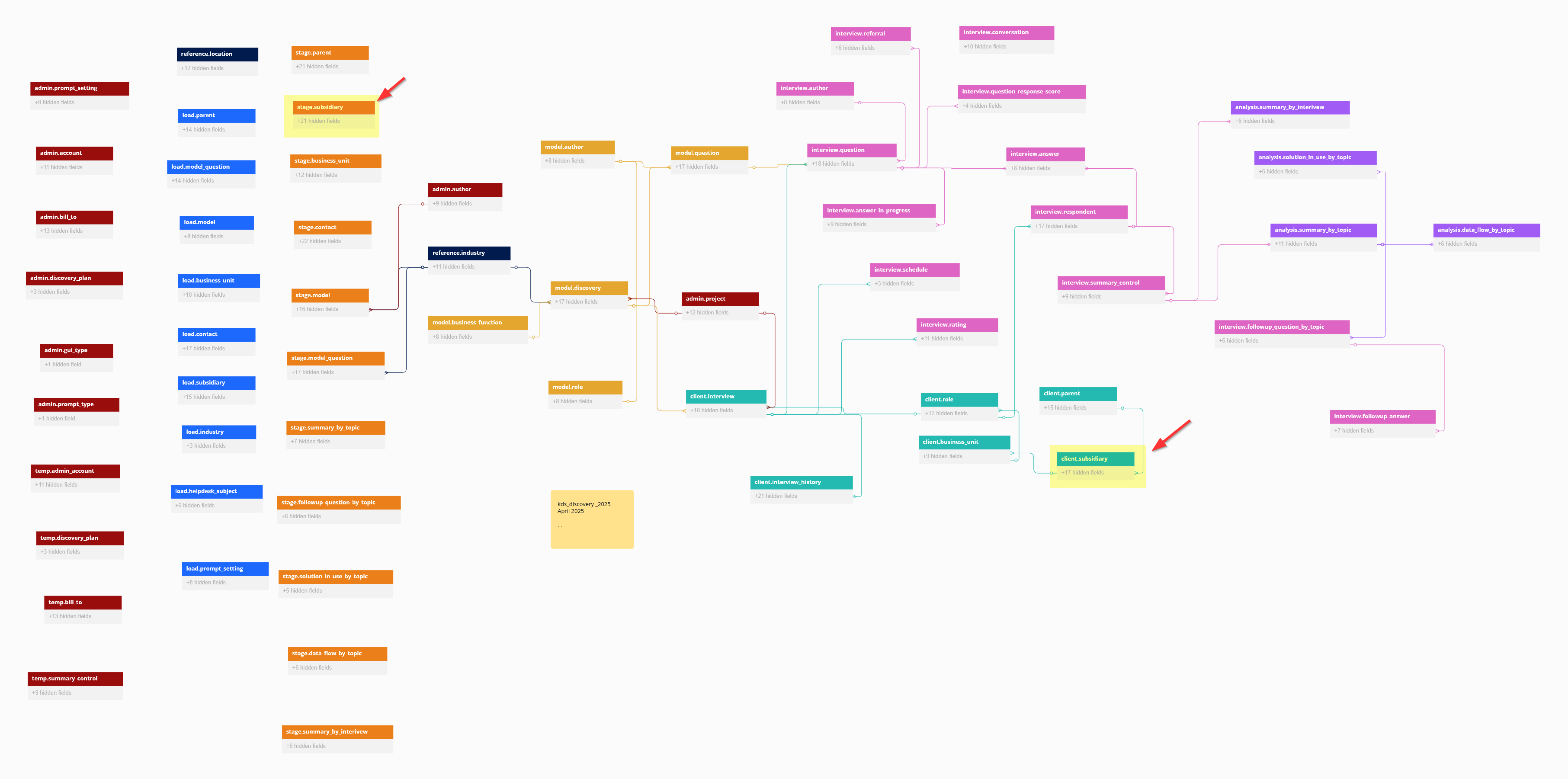
The kDS Discovery Database has a staging table (stage.subsidiary) with potential new subsidiary companies, and we need to insert only the subsidiaries that don't already exist in our client table (client.subsidiary). This is a classic "find what's missing" problem in SQL, and one we frequently encounter in the kDS Discovery App's data pipeline.
Two Solutions
Approach 1: LEFT JOIN with NULL Check
SELECT
s.organization_type, p.parent_id, s.name_, s.stock_symbol,
s.industry_hash_id, s.product_service, s.annual_revenue,
s.employee_total, s.website_, s.location_, s.source_,
CURRENT_DATE, s.created_by, s.modified_date, s.modified_by
FROM stage.subsidiary s
INNER JOIN client.parent p ON s.parent_name = p.name_
LEFT OUTER JOIN client.subsidiary cs ON cs.name_ = s.name_
WHERE cs.name_ IS NULL;This query joins the staging table with the client table and then filters for rows where no match was found (indicated by NULL values).
Approach 2: NOT EXISTS with Correlated Subquery
SELECT
s.organization_type, p.parent_id, s.name_, s.stock_symbol,
s.industry_hash_id, s.product_service, s.annual_revenue,
s.employee_total, s.website_, s.location_, s.source_,
CURRENT_DATE, s.created_by, s.modified_date, s.modified_by
FROM stage.subsidiary s
INNER JOIN client.parent p ON s.parent_name = p.name_
WHERE NOT EXISTS (
SELECT 1
FROM client.subsidiary cs
WHERE cs.name_ = s.name_
);This alternative uses a correlated subquery with NOT EXISTS to find records that don't have a match in the client table.
Performance Considerations
In theory, the NOT EXISTS approach often has advantages:
- Early termination: NOT EXISTS can stop evaluation as soon as it finds a single matching row in the correlated subquery.
- Memory efficiency: LEFT JOIN potentially creates a larger intermediate result set before filtering.
- Optimizer behavior: Most modern query optimizers handle EXISTS/NOT EXISTS queries efficiently.
- Index utilization: Both approaches can use indexes, but NOT EXISTS might use them more efficiently.
The Real Test: EXPLAIN ANALYZE
I used PostgreSQL's EXPLAIN ANALYZE to examine the execution plans and performance of both queries. Running it is simple. It just requires placing EXPLAIN ANALYZE in front of the SELECT command prior to running the query.
The Results
NOT EXISTS Query Results:
Hash Join (cost=21.19..31.75 rows=1 width=1576) (actual time=0.054..0.057 rows=0 loops=1)
Hash Cond: ((p.name_)::text = (s.parent_name)::text)
-> Seq Scan on parent p (cost=0.00..10.40 rows=40 width=226) (actual time=0.013..0.014 rows=1 loops=1)
-> Hash (cost=21.18..21.18 rows=1 width=1766) (actual time=0.035..0.036 rows=0 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 8kB
-> Hash Anti Join (cost=10.90..21.18 rows=1 width=1766) (actual time=0.034..0.035 rows=0 loops=1)
Hash Cond: ((s.name_)::text = (cs.name_)::text)
-> Seq Scan on subsidiary s (cost=0.00..10.20 rows=20 width=1766) (actual time=0.005..0.008 rows=4 loops=1)
-> Hash (cost=10.40..10.40 rows=40 width=210) (actual time=0.016..0.016 rows=5 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on subsidiary cs (cost=0.00..10.40 rows=40 width=210) (actual time=0.006..0.009 rows=5 loops=1)
Planning Time: 0.736 ms
Execution Time: 0.111 msLEFT JOIN Query Results:
Hash Join (cost=21.19..31.75 rows=1 width=1576) (actual time=0.145..0.150 rows=0 loops=1)
Hash Cond: ((p.name_)::text = (s.parent_name)::text)
-> Seq Scan on parent p (cost=0.00..10.40 rows=40 width=226) (actual time=0.037..0.038 rows=1 loops=1)
-> Hash (cost=21.18..21.18 rows=1 width=1766) (actual time=0.087..0.091 rows=0 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 8kB
-> Hash Anti Join (cost=10.90..21.18 rows=1 width=1766) (actual time=0.086..0.089 rows=0 loops=1)
Hash Cond: ((s.name_)::text = (cs.name_)::text)
-> Seq Scan on subsidiary s (cost=0.00..10.20 rows=20 width=1766) (actual time=0.018..0.039 rows=4 loops=1)
-> Hash (cost=10.40..10.40 rows=40 width=210) (actual time=0.028..0.029 rows=5 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 9kB
-> Seq Scan on subsidiary cs (cost=0.00..10.40 rows=40 width=210) (actual time=0.011..0.015 rows=5 loops=1)
Planning Time: 2.581 ms
Execution Time: 0.244 msAnalysis of the Results
Examining these execution plans reveals some interesting insights:
1. Same Execution Strategy
Surprisingly, PostgreSQL's optimizer chose the same execution plan for both queries. In both cases, it used a Hash Anti Join to identify rows from subsidiary s that don't have matching rows in subsidiary cs.
This suggests that PostgreSQL is intelligent enough to recognize that both query patterns are logically equivalent and convert them to the same internal representation.
2. Performance Differences
Despite using the same execution plan, the queries showed significant performance differences:
| Metric | NOT EXISTS Query | LEFT JOIN Query | Difference |
|---|---|---|---|
| Execution Time | 0.111 ms | 0.244 ms | NOT EXISTS is 2.2× faster |
| Planning Time | 0.736 ms | 2.581 ms | NOT EXISTS is 3.5× faster |
| Hash Anti Join Time | 0.034..0.035 ms | 0.086..0.089 ms | NOT EXISTS is 2.5× faster |
3. Why the Performance Difference?
Even though both queries resulted in the same execution plan, the NOT EXISTS version performed significantly better. This suggests several factors at work:
- The NOT EXISTS syntax might be more efficient for PostgreSQL to parse and optimize
- Internal processing overhead differences between the two approaches
- Memory management and caching effects
Conclusion: NOT EXISTS Performs Better
In this specific case, the NOT EXISTS approach is clearly more efficient. While PostgreSQL was smart enough to transform both queries into the same execution plan (a Hash Anti Join), the NOT EXISTS syntax resulted in both faster planning and execution times.
Key takeaways:
- Modern database optimizers are sophisticated but still respond differently to different SQL patterns.
- The NOT EXISTS approach is likely more direct for the optimizer to process.
- Always test with EXPLAIN ANALYZE on your specific database and data volumes.
While the difference in this example (0.13ms) might seem small, it can become significant when working with larger datasets or in performance-critical applications. A 2.2× performance improvement can make a substantial difference in high-volume systems.
As with many aspects of database optimization, the best approach depends on your specific scenario, database system, and data characteristics. Testing is essential.
Please don't forget my company, kDS LLC, is actively seeking organizations interested in adopting a beta version of the kDS Data Source Discovery App. If your organization is interested, please let us know. We’d love to collaborate. Tell us in the comments below or email us at info@keeshinds.com
As always, thanks for stopping by!