Designing a Chatbot Interview App Database – Part 5: Mapping LLM-Generated Data to Real-World Data
by DL Keeshin
October 17, 2024
{kind=link}
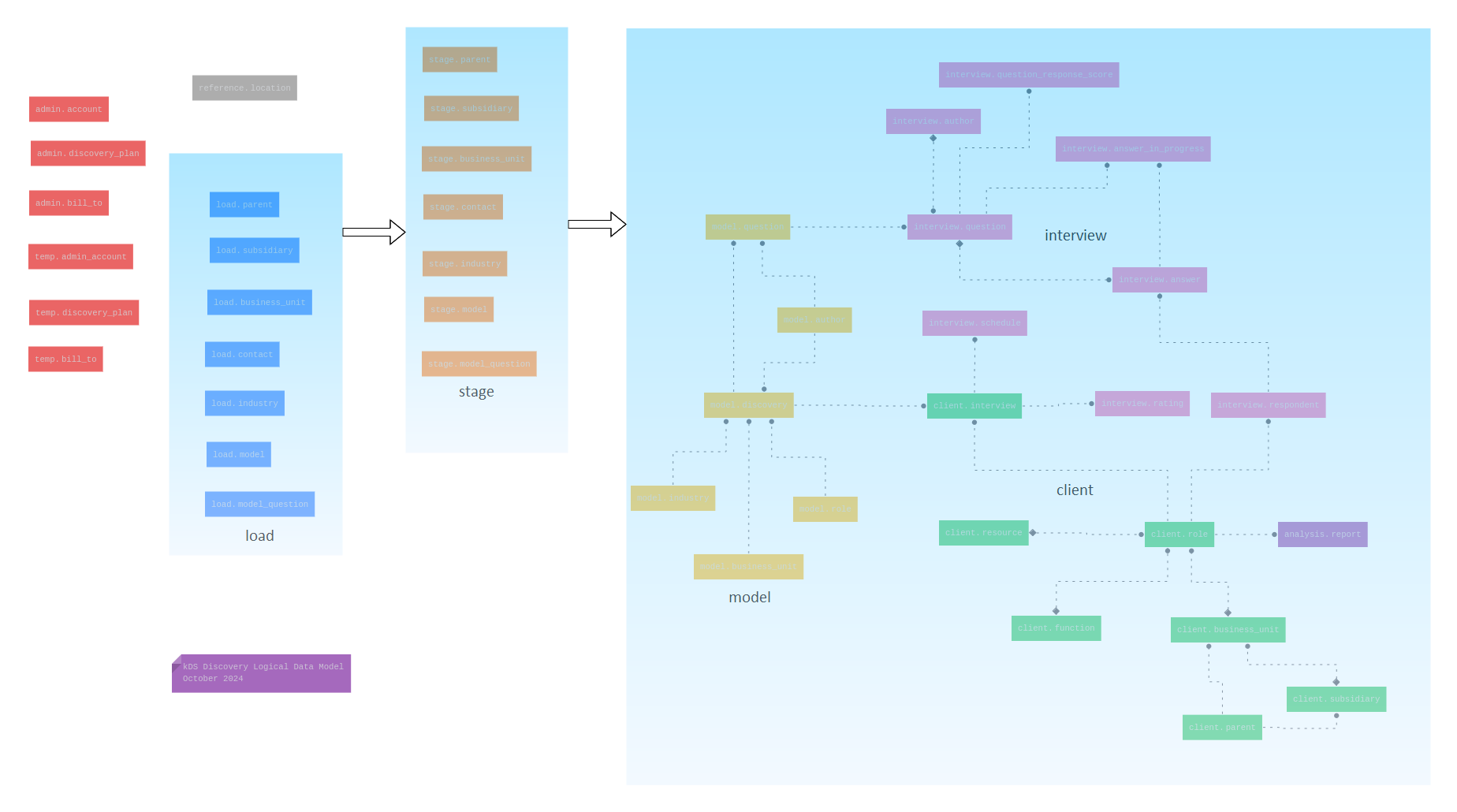
In my last post, I discussed and demonstrated how to load the model schema tables, which are shown in yellow in the above diagram. In this Part 5 of the series, I discuss the how and why of mapping LLM-generated data to real-world data.
Mapping LLM to Real-World Data
Mapping LLM-generated data to real-world data involves bridging the gap between unstructured language and structured data formats. This process requires techniques such as entity extraction, schema mapping, and validation to ensure that the outputs from the LLM can be integrated effectively into existing systems.
Why Map Real-World Data to LLM-Generated Data?
- Consistency in Context: By using data that the LLM has already generated or transformed, you maintain a consistent context. LLMs perform better when they follow a continuous narrative without switching between different data formats or contexts.
- Data Simplification and Language Alignment: Real-world data mapped to LLM output is often simplified and framed in a more digestible format for the LLM. Since LLMs excel at processing natural language, aligning data with this format helps them deliver more accurate analysis.
- Tailored Prompts for Targeted Analysis: Re-prompting the LLM with mapped data allows for more specific and targeted prompts, improving its ability to perform deeper, more precise analyses.
- Avoiding Ambiguity: Real-world data can include jargon or technical terms that the LLM may misinterpret. Mapping data in a more natural language form helps minimize ambiguity.
- Error Correction and Data Smoothing: During initial mapping, the LLM might introduce small errors. Re-prompting with the mapped data allows the LLM to "revisit" and correct these, leading to smoother and more refined outputs.
It's All About the Source
In schema mapping, client schema data is sourced directly from users, representing the real-world organizational structures they provide, such as parent companies, subsidiaries, business units, and roles. The model schema, however, is sourced via the LLM and reflects insights or inferences the model generates, such as discovery questions or analysis points.
Mapping these two ensures that client-provided data aligns with model-generated insights, leading to coherent and actionable system outcomes.
Script Notes
This SQL script handles data loading from the staging schema into the production client and interview schemas.
- Client Schema Tables Loaded:
client.parentclient.subsidiaryclient.business_unitclient.roleclient.interview
- Interview Schema Tables Loaded:
interview.authorinterview.respondentinterview.question
The following INSERT statement inserts respondents from stage.contact, linking them to roles via client.role and associating them with business units, subsidiaries, and parents.
INSERT INTO interview.respondent (
email_,
role_id,
description_,
respondent_,
project_sponsor,
location_reference,
first_name,
last_name,
title_,
phone_,
create_date
)
SELECT
c.email_,
c.role_id,
c.role_,
c.respondent_,
c.project_sponsor,
c.location_reference,
c.first_name,
c.last_name,
c.title_,
c.phone_,
CURRENT_DATE
FROM (
SELECT DISTINCT ON (email_, role_, business_unit, subsidiary_, parent_)
c.email_,
cr.role_id,
c.role_,
c.respondent_,
c.project_sponsor,
c.location_reference,
c.first_name,
c.last_name,
c.title_,
c.phone_
FROM stage.contact c
LEFT JOIN client.role cr
ON cr.description_ = c.role_
LEFT JOIN client.business_unit bu
ON bu.name_ = c.business_unit
LEFT JOIN client.subsidiary sub
ON sub.name_ = COALESCE(c.subsidiary_, '')
LEFT JOIN client.parent p
ON p.name_ = c.parent_
WHERE
bu.unit_id IS NOT NULL
AND p.parent_id IS NOT NULL
) AS c;
The last INSERT statement in the script brings together what this post is all about. It INSERTS data into the client.interview table by linking several key attributes from various tables, ensuring that the interview data is well-integrated with the organizational structure and roles in the system:
INSERT INTO client.interview (
role_id,
model_id,
frequency_,
source_,
create_date
)
SELECT
cr.role_id,
md.model_id,
'one-time' AS frequency_,
'system' AS source_,
CURRENT_DATE AS create_date
FROM interview.respondent ir
JOIN client.role cr ON cr.role_id = ir.role_id
JOIN stage.contact sc ON ir.email_ = sc.email_
JOIN model.discovery md ON sc.model_reference = md.role_id
JOIN stage.business_unit sbu ON sbu.model_reference = md.unit_id;
To put it simply,this INSERT statement joins the LLM generated model interview data to the real-world client interview data.
Final Thoughts
This part of the series explores the process and benefits of mapping LLM-generated data to real-world data, focusing on techniques like entity extraction, schema mapping, and validation. By aligning client-provided data with model-generated insights, the system ensures consistency and enhances the LLM’s analytical capabilities.
Next time, I'll cover generating and loading answers.
As always,thanks for reading!
If you want to try creating and loading the kds_discovery database with all of the data described here, see "Database Installation" in the README file here.